
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Kubernetes
- python
- 프로그래머스
- DeepLearning
- pep8
- torchserve
- 네이버AItech
- Matplotlib
- leetcode
- NaverAItech
- PytorchLightning
- 알고리즘
- GitHub Action
- datascience
- FDS
- github
- autoencoder
- GCP
- NLP
- pytorch
- 코딩테스트
- Kaggle
- rnn
- GIT
- wandb
- vscode
- FastAPI
- 완전탐색
- docker
- 백준
- Today
- Total
Sangmun
[DL basic] LSTM & GRU 본문
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Understanding LSTM Networks -- colah's blog
Posted on August 27, 2015 <!-- by colah --> Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking
colah.github.io
개요
RNN은 시퀀스가 길어짐에 따라 gradient vanishing or exploding의 문제가 있고 또 오래된 타임스텝의 정보를 기억하기 힘들다는 한계점이 있다.
이러한 한계점을 극복하고자 LSTM이 제안 되었으며 LSTM은 input(X)와 단기기억을 담당하는 hidden state 그리고 좀 더 오래된 타임스텝의 정보를 담고자 cell state가 하나의 cell의 input으로 들어오게 된다.
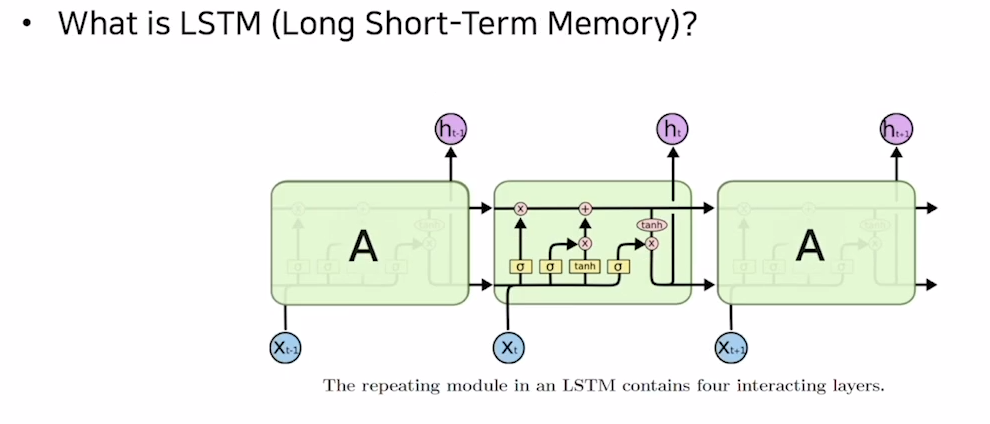
LSTM(Long Short-Term Memory)
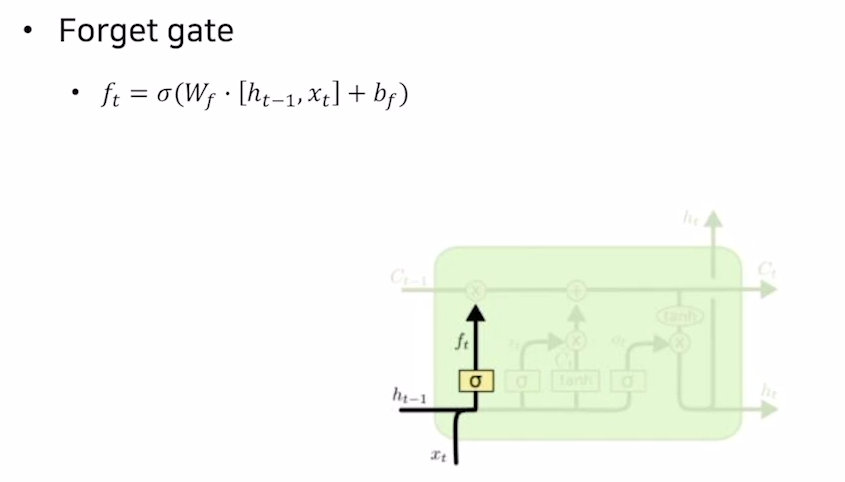
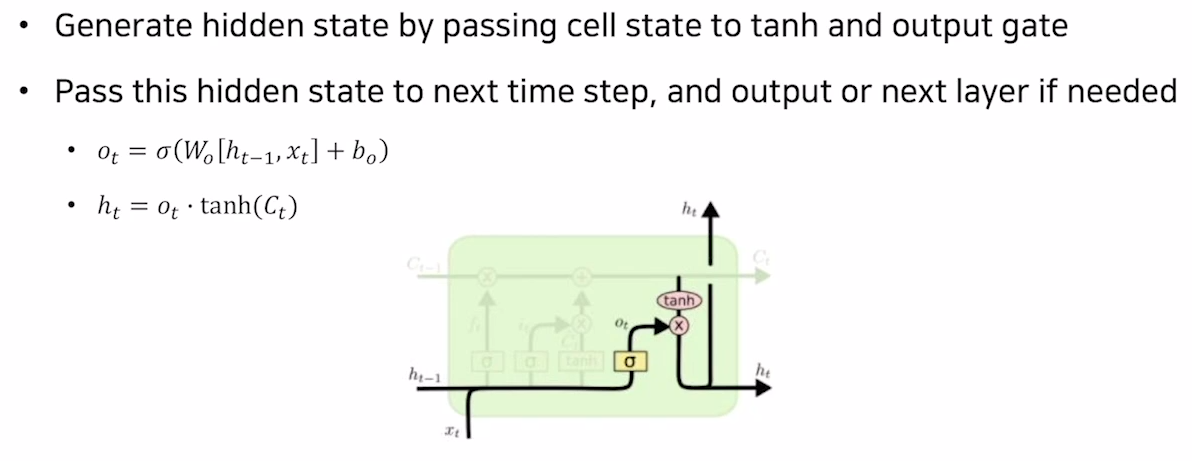
LSTM은 장단기 타입스텝을 기억하기 위해 hidden state와 cell state를 input으로 받고 4개의 gate를 거쳐 다음 타임스텝의 hidden state와 cell state를 출력하게 된다.
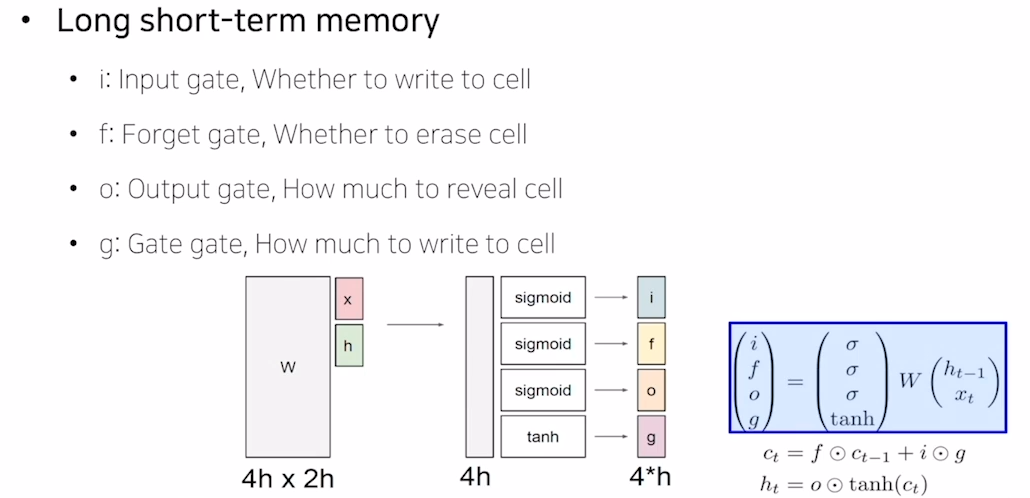
구체적으로는 아래의 이미지와 같이 각각의 gate들이 계산되게 된다.
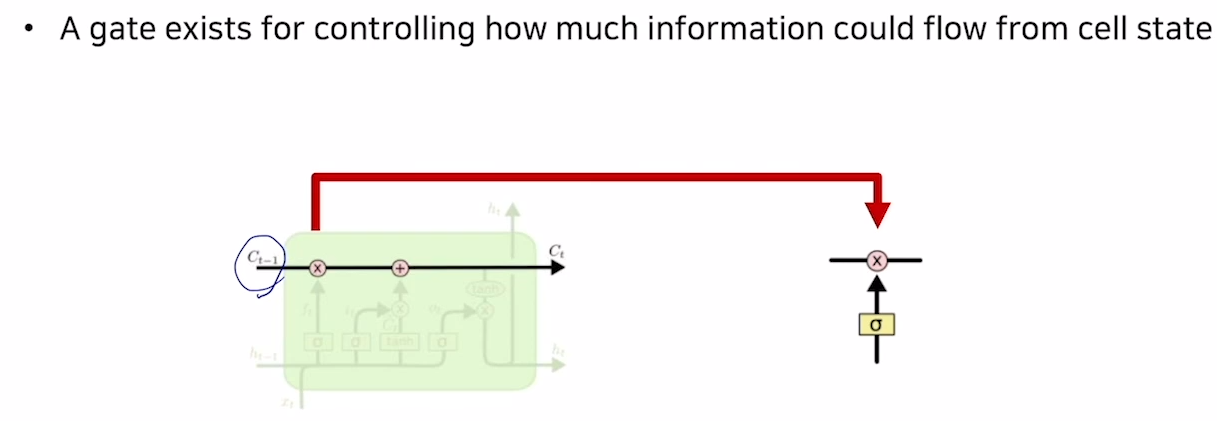
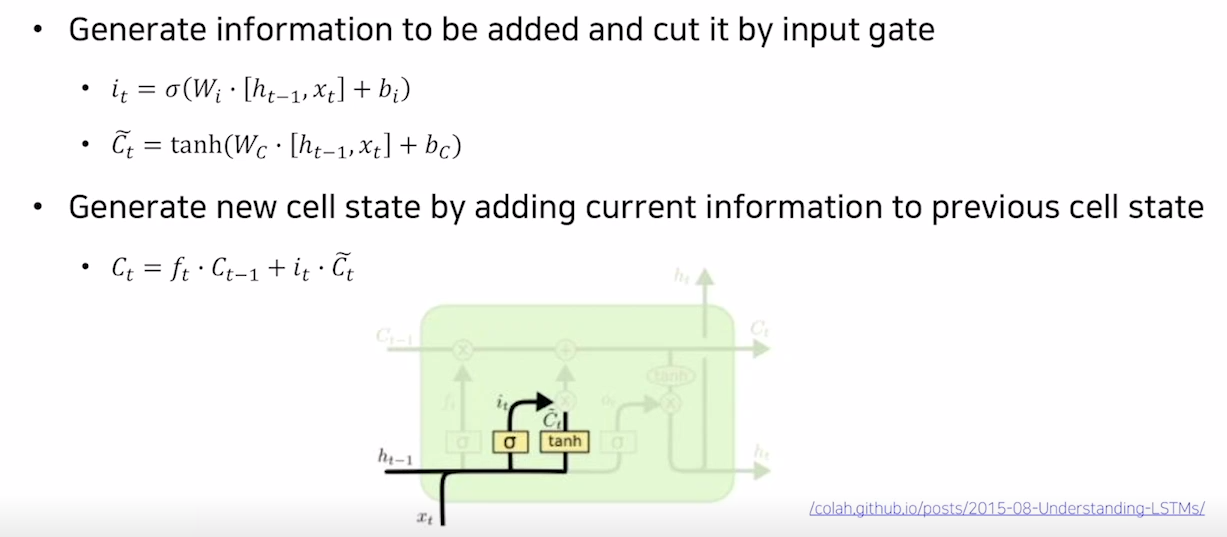
GRU(Gated Recurrent Unit)
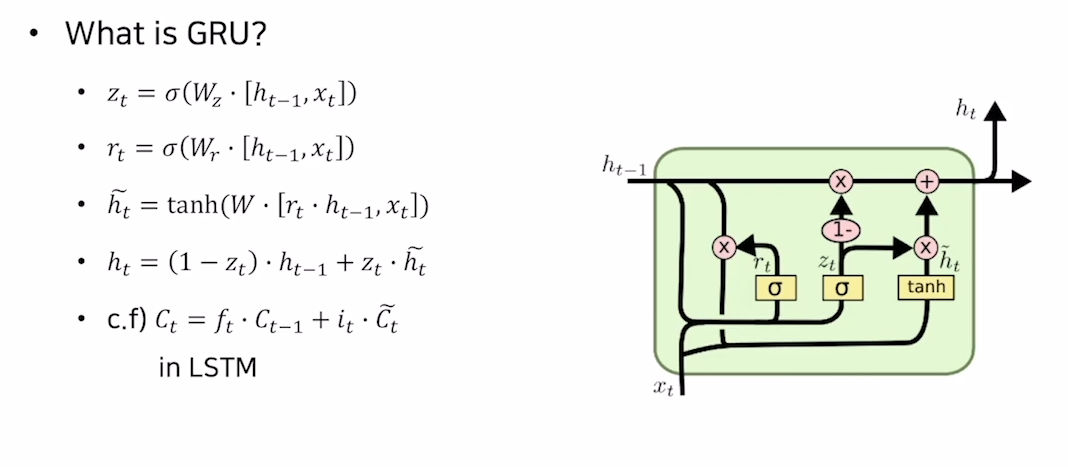
GRU는 LSTM의 변형된 버전으로 cell state를 출력값으로 가지지 않는다. LSTM보다 좀 더 경량화된 버전이라고 보면 될 듯 하다.
BPTT in LSTM
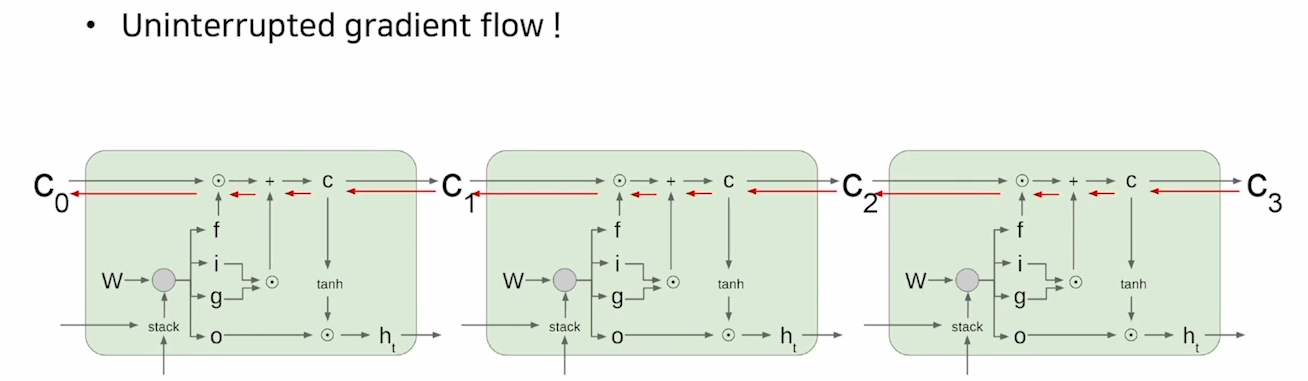
기존의 RNN은 아래의 그림과 같이 시퀀스 길이가 늘어남에 따라 아래의 항이 계속 곱해지므로 gradient vanishing or exploding의 문제가 발생하기 쉬웠다.

하지만 LSTM에서는 cell state를 정보들을 단순히 내적과 덧셈을 함으로써 위와 같은 vanilla rnn의 문제를 해결하였다고 볼 수 있다.
'네이버 AI 부스트캠프 4기' 카테고리의 다른 글
| Pytorch Lightning 사용법 예제로 알아보기 (0) | 2022.10.25 |
|---|---|
| [NLP] Byte Pair Encoding (0) | 2022.10.20 |
| [NLP] Beam Search (1) | 2022.10.15 |
| [NLP] Perplexity(PPL) and BLEU score (0) | 2022.10.14 |
| [NLP] Seq2Seq (0) | 2022.10.04 |


