
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- GCP
- rnn
- GitHub Action
- Kubernetes
- autoencoder
- 백준
- NaverAItech
- 완전탐색
- DeepLearning
- NLP
- torchserve
- datascience
- leetcode
- GIT
- PytorchLightning
- pytorch
- 네이버AItech
- pep8
- 프로그래머스
- wandb
- FastAPI
- Matplotlib
- FDS
- github
- 알고리즘
- docker
- python
- vscode
- Kaggle
- 코딩테스트
- Today
- Total
Sangmun
[NLP] Perplexity(PPL) and BLEU score 본문
5) 펄플렉서티(Perplexity, PPL)
두 개의 모델 A, B가 있을 때 이 모델의 성능은 어떻게 비교할 수 있을까요? 두 개의 모델을 오타 교정, 기계 번역 등의 평가에 투입해볼 수 있겠습니다. 그리고 두 모델 ...
wikidocs.net
BLEU 논문
https://aclanthology.org/P02-1040.pdf
PPL
PPL은 언어 모델의 평가 metric 중의 하나로 perplexed는 '헷갈리는' 의미를 가지고 있으며 이는 매 타입스텝 마다 몇개의 가능성 있는 output을 가지고 헷갈리냐고 이해할 수 있다. 즉 PPL은 낮을 수록 성능이 좋다라는 의미가 된다.
아래는 PPL의 수식이며 매 타입스텝의 출력값으로 나온 확률 값을 기하평균 해준다.
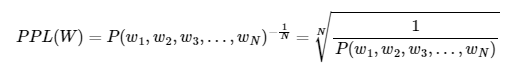

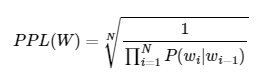
PPL과 Cross entropy
PPL의 공식에서 Cross entropy loss와의 유사점을 찾아 볼 수 있으며 공식을 풀어보면 아래와 같은 수식이 된다.
$$ CrossEntropyLoss(x_{1:n};\theta) \approx -\frac{1}{n}\sum_{i=1}^{n}logP(x_i|x_{<i};\theta) $$
$$ = -\frac{1}{n}log\prod_{i=1}^{n}P(x_{i}|x_{<i};\theta) $$
$$ = log \sqrt[n]{\frac{1}{\prod_{i=1}^{n}P(x_i|x_{<i};\theta)}} $$
$$ = logPPL(x_{i:n};\theta) $$
Cross entropy loss는 logPPL과 같음을 알 수 있다.
PPL의 한계
이 처럼 PPL은 언어 모델간 동일한 성능 평가 지표를 제안하였고 유용하게 사용되는 지표이지만 번역 품질의 성능을 제대로 반영하지 못한다는 단점이 있다.
예를 들어 아래와 같은 예시가 있다고 하면
원문 : I like to listen to music
정답 : 나는 음악을 듣는 것을 좋아한다.
model1 : 좋아한다 나는 음악을 듣는 것을
model2 : 나는 음식을 먹는 것을 좋아한다.
한국어는 교착어이고 교착어의 성질에 따르면 단어의 어순이 바뀌어도 어느정도 의미가 통하게 된다. 따라서 model1은 매 타임스텝마다 나와야 하는 단어가 나오지는 않았지만 적절한 번역이라고 할 수 있다. 하지만 PPL을 기준으로 하면 model2가 매 타입스텝마다 나와야 하는 단어가 더 많이 나왔기 때문에 좋은 모델로 분류가 된다.
Precision & recall
다음으로 언어 모델을 평가하는 방법으로는 precision, recall 그리고 precision과 recall을 조화평균낸 F-measure가 있다.

precision 예측한 문장에서 Reference(ground truth)에 있는 단어를 몇개를 포함했나로 계산을 하고(순서는 고려안함)
recall은 Reference(ground truth)에 포함된 단어 중 몇개를 예측했나로 계산한다(역시 단어의 순서는 고려 안함)
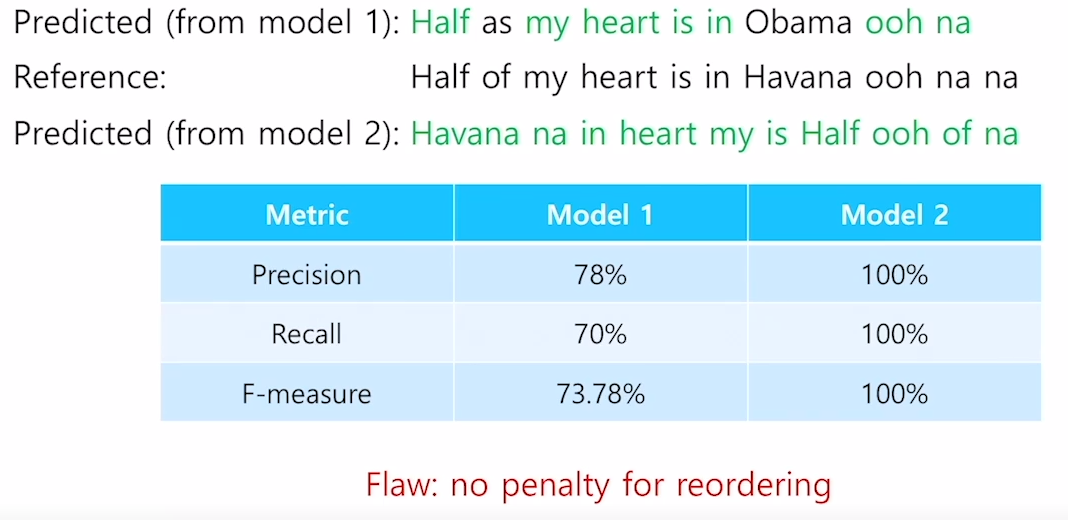
하지만 위의 그림과 같이 순서를 고려안했을때 model2와 같은 실제로는 예측을 제대로 하지 못했지만 precision, recall, f-measure 모두 100점이 나와 더 좋은 모델로 분류되는 케이스가 발생하는 한계점이 존재하였다.
BLEU(BiLingual Evaluation Understudy)
이러한 한계점을 보안하기 위해서 BLEU score이 제안되었다.

BLEU score는 크게 N-gram precision과 brevity penalty로 나눌 수 있으면 두값을 곱한값이 BLEU score다
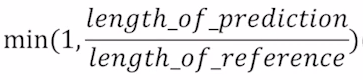
brevity score는 예측된 문장의 길이가 input으로 주어진 문장의 길이보다 너무 짧은 경우 패널티를 주기 위함이다.

N-gram precision은 unigram 부터 fourgram의 precision의 값을 구해주고 각각의 값에 기하평균을 내준 값이다.
BLEU 계산 예시

위의 그림은 계산 예시를 설명한 그림이며 Precision (2-gram)의 예시를 들어보자면
model1의 출력값을 bi-gram으로 나누어 보면 결과는 아래와 같다.
[[Half, as],[as, my],[my, heart],[heart, is],[is, in],[in, Obama],[Obama, ooh],[ooh, na]] 출력값의 길이는 8 이고
Reference(ground truth) 문장을 bi-gram으로 나누었을때 전체에서 [[my, heart],[heart, is],[is, in],[ooh,na]] 이 포함되며 길이는 4이다.
따라서 Precision (2-gram)을 계산하면 4/8 = 1/2 값이 계산된다.
위와 같은 방법으로 four-gram 까지 precision을 구하고 Brevity penalty를 구하여 곱해주면 52라는 BLEU score를 얻게 된다.
'네이버 AI 부스트캠프 4기' 카테고리의 다른 글
| [DL basic] LSTM & GRU (0) | 2022.10.15 |
|---|---|
| [NLP] Beam Search (1) | 2022.10.15 |
| [NLP] Seq2Seq (0) | 2022.10.04 |
| [NLP] Transformer (0) | 2022.10.03 |
| Pytorch Custom Dataset (2) | 2022.09.30 |



