
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- NLP
- FDS
- autoencoder
- Kaggle
- GitHub Action
- 알고리즘
- FastAPI
- 프로그래머스
- datascience
- 코딩테스트
- docker
- Matplotlib
- vscode
- PytorchLightning
- python
- pep8
- wandb
- github
- DeepLearning
- leetcode
- rnn
- GCP
- 완전탐색
- 네이버AItech
- NaverAItech
- GIT
- 백준
- torchserve
- Kubernetes
- pytorch
- Today
- Total
Sangmun
Pytorch Lightning 사용법 예제로 알아보기 본문
Pytorch를 사용하다보면 Tensorflow보다는 사용하기가 편하다는 느낌을 받을 수 있는 데 사용하기 편한 만큼 뭔가 체계화된 구조가 없고 매번 비슷한 코드가 반복된다는 느낌이 있다. (gradien descent라든지.. ,dataloader 부분이라든지..)
따라서 Pytorch Lightning은 Pytorch코드에 대한 high level interface를 제공하고 복잡한 코드들을 추상화하는데 도움을 주기 위해 만들어진 패키지이다. (아래는 Pytorch document)
https://pytorch-lightning.readthedocs.io/en/stable/
Welcome to ⚡ PyTorch Lightning — PyTorch Lightning 1.7.7 documentation
Shortcuts
pytorch-lightning.readthedocs.io
Mnist 예제를 통해 어떠한 차이점이 있는지 알아보자
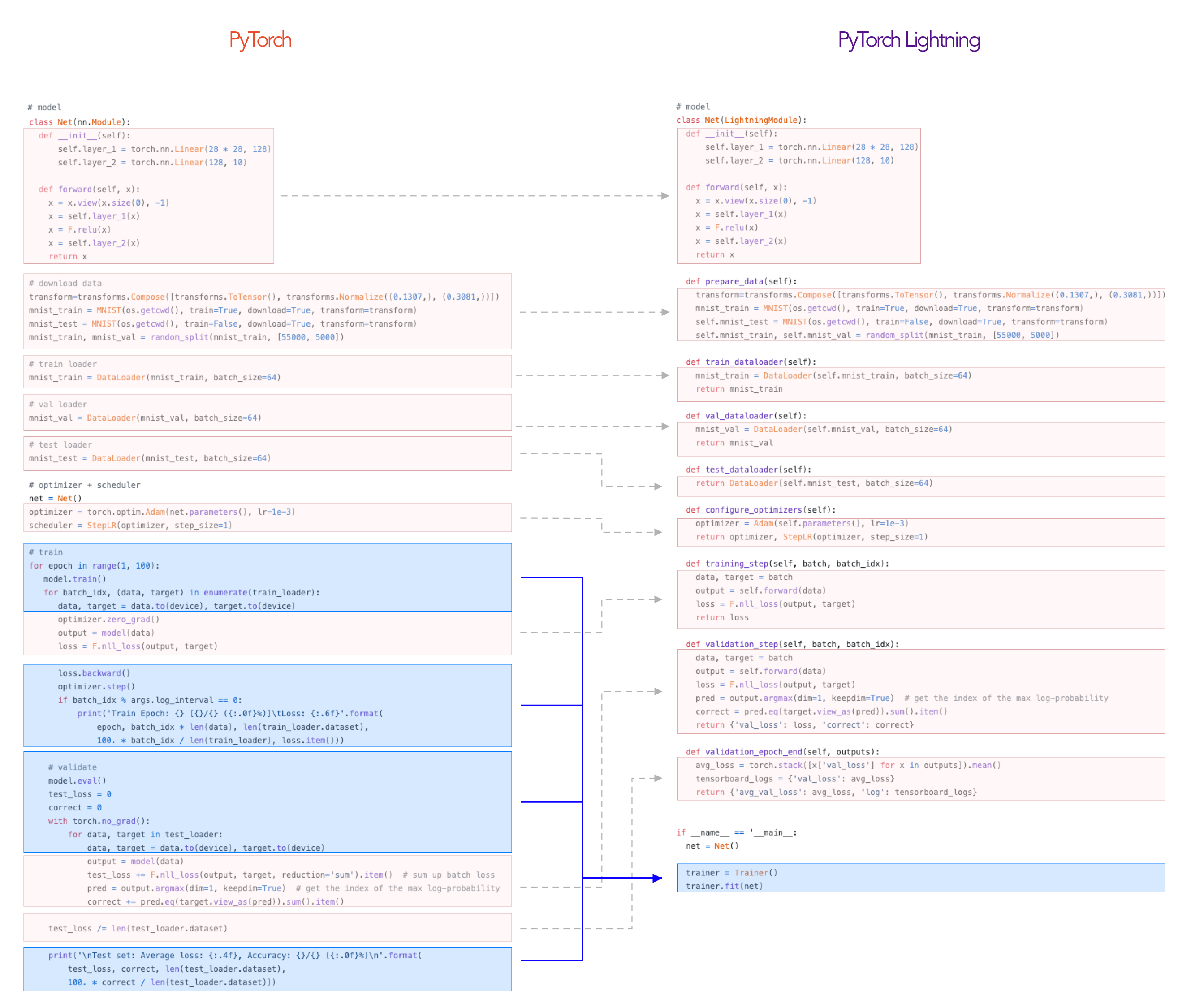
위 이미지는 Pytorch Lightning document에 있는 비교 코드인데 data prepare 및 train 기능이 Net class에 전부 포함되어 추상화 되어있고, train과 eval 부분의 매번 반복되는 계산 부분도 대부분 추상화가 된 것을 확인할 수 있다.
* Data preparation
기존 Pytorch 코드에서는 Data preparation관련 기능들이 추상화 되어있지 않고 또한 기능이 추가되면 가독성이 떨어진다는 문제점이 있었다.
# Pytorch
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
mnist_train = MNIST(os.getcwd(), train=True, download=True, transform=transform)
mnist_test = MNIST(os.getcwd(), train=False, download=True, transform=transform)
mnist_train, mnist_val = random_split(mnist_train, [55000, 5000])
mnist_train_dataloader = DataLoader(mnist_train, batch_size=64, shuffle=True) # <-- shuffle is important!
mnist_val_dataloader = DataLoader(mnist_val, batch_size=64)
mnist_test_dataloader = DataLoader(mnist_test, batch_size=64)
반면에 Pytorch Lightning에서는 Data preparation과 관련된 기능을 하나의 class로 구현하였다.
# Pytorch Lightning
class MNSTDataModule(pl.LightningDataModule):
def __init__(self,
batch_size: int = 32,
):
super().__init__()
self.batch_size = batch_size
self.transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081))])
def prepare_data(self):
MNIST(os.getcwd(), train=True, download=True)
MNIST(os.getcwd(), train=False, download=True)
def setup(self, stage = None):
# Pytorch 에서는 stage로 train/eval/test를 구분
if stage == "fit" or stage is None:
mnist_full = MNIST(os.getcwd(), train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
if stage == "test" or stage is None:
self.mnist_test = MNIST(os.getcwd(), train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)
* Model & Optimizer
다음은 Pytorch 코드의 모델 정의와 Optimzer 및 scheduler이다.
# Pytorch
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer_1 = nn.Linear(28 * 28, 128)
self.layer_2 = nn.Linear(128, 256)
self.layer_3 = nn.Linear(256, 10)
def forward(self, x):
batch_size, channelds, width, height = x.size()
x = x.view(batch_size, -1)
x = self.layer_1(x)
x = torch.relu(x)
x = self.layer_2(x)
x = torch.relu(x)
x = self.layer_3(x)
x = torch.log_softmax(x, dim=1)
return x
# Model & Optimizer
net = Net()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=1)아래는 Lightning 코드이며 Model과 Optimizer, train, test가 전부 각각의 함수에 추상화되어 구현되어 있음을 확인할 수 있다. 지금 까지 보면 코드들이 추상화된 것은 좋은데 오히려 코드 길이가 길어진 느낌이다.. 아래를 보자
# Pytorch Lightning
class PLNet(pl.LightningModule):
def __init__(self):
super(PLNet, self).__init__()
self.layer_1 = nn.Linear(28 * 28, 128)
self.layer_2 = nn.Linear(128, 256)
self.layer_3 = nn.Linear(256, 10)
def forward(self, x):
batch_size, channelds, width, height = x.size()
x = x.view(batch_size, -1)
x = self.layer_1(x)
x = torch.relu(x)
x = self.layer_2(x)
x = torch.relu(x)
x = self.layer_3(x)
x = torch.log_softmax(x, dim=1)
return x
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=1)
return [optimizer], [scheduler]
def training_step(self, batch, batch_idx):
data, target = batch
output = self(data)
loss = F.nll_loss(output, target)
return loss
def validation_step(self, batch, batch_idx):
data, target = batch
output = self(data)
loss = F.nll_loss(output, target)
pred = output.argmax(dim=1, keepdim=True)
correct = pred.eq(target.view_as(pred)).sum().item()
return {"val_loss" : loss, "correct" : correct}
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
self.log('val_loss', avg_loss)
self.log('avg_val_loss', avg_loss)
def test_step(self, batch, batch_idx):
data, target = batch
output = self(data)
pred = output.argmax(dim=1, keepdim=True)
correct = pred.eq(target.view_as(pred)).sum().item()/ len(target)
return {"correct": correct}
def test_epoch_end(self, outputs):
all_correct = sum([output["correct"] for output in outputs])
accuracy = all_correct / len(outputs)
self.log("accuracy", accuracy)
* train & test 코드
아래 처럼 pytorch 코드는 매 Epoch 및 step마다 gradient descent와 metric을 계산해주는 코드가 노출되어있다.
# Pytorch
# Train & Validation
for epoch in range(1, 3):
net.train()
for batch_idx, (data, target) in enumerate(mnist_train_dataloader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = net(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print("Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch, batch_idx * len(data), len(mnist_train_dataloader.dataset),
100. * batch_idx / len(mnist_train_dataloader), loss.item()
))
net.eval()
val_loss = 0
correct = 0
with torch.no_grad():
for data, target in mnist_val_dataloader:
data, target = data.to(device), target.to(device)
output = net(data)
val_loss = F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
val_loss /= len(mnist_val_dataloader.dataset)
print("\n[Validation] Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
val_loss, correct, len(mnist_val_dataloader.dataset),
100. * correct / len(mnist_val_dataloader.dataset)
))
# TEST
net.eval()
correct = 0
with torch.no_grad():
for data, target in mnist_test_dataloader:
data, target = data.to(device), target.to(device)
output = net(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print("\n[Test] Accuracy: {}/{} ({:.0f}%)\n".format(
correct, len(mnist_test_dataloader.dataset),
100. * correct / len(mnist_test_dataloader.dataset)
))반면에 Pytorch lightning은 train 및 test가 전부 한 줄에 구현이 되어있다.
# Pytorch Lightning
# Data Preparation
dm = MNSTDataModule()
pl_net = PLNet()
# Train & Validation
trainer = pl.Trainer(max_epochs = 3)
trainer.fit(pl_net, datamodule=dm)
# Test
trainer.test(datamodule=dm)전체 코드 : https://colab.research.google.com/drive/1Bw-XqZEgK0jDIUcjcRlnadl-xewnQ0fv?usp=sharing
* Pytorch Lightning vs Ignite
출처 : https://neptune.ai/blog/pytorch-lightning-vs-ignite-differences
Pytorch 코드를 추상화하기 위한 프레임워크로 Pytorch Ignite라는 프레임워크도 있다. Pytorch Ignite 프레임워크가 오피셜 한 프레임워크인 것으로 알고 있는데 어째 Ignite는 쓰는 걸 본 적이 없는 것 같다. 아래는 간단한 비교표이다.
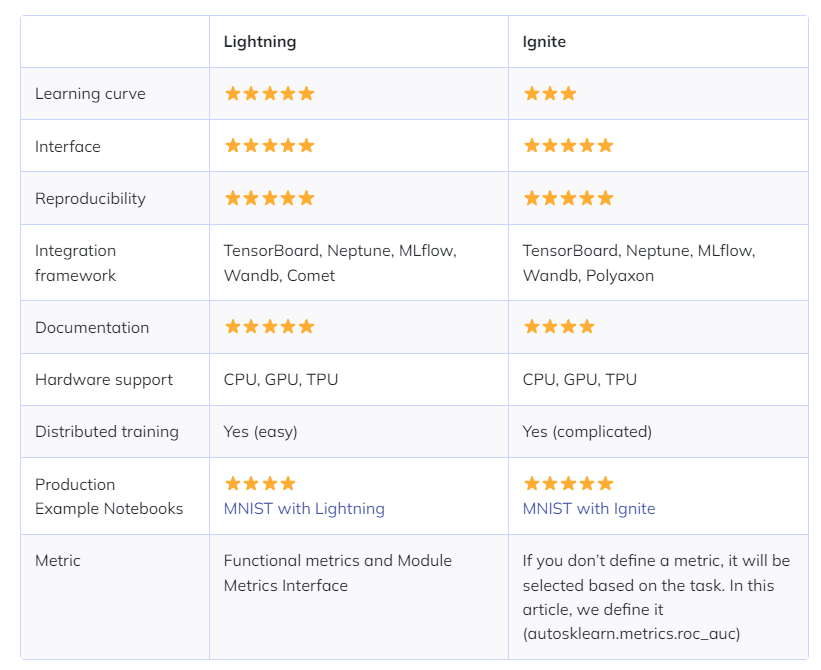
위의 블로그에서는 결론적으로 Ignite가 좀 더 유연하고 기존의 Pytorch 코드의 구조를 활용 할 수 있으며, Lightning은 빠른 프로토타이핑과 디자인, 또는 실험적이 시도에 좀 더 적합하다고 한다.
'네이버 AI 부스트캠프 4기' 카테고리의 다른 글
| BN 적용해서 학습 이후 실제 사용시에 주의할 점은 (0) | 2022.12.15 |
|---|---|
| [NLP] Byte Pair Encoding (0) | 2022.10.20 |
| [DL basic] LSTM & GRU (0) | 2022.10.15 |
| [NLP] Beam Search (1) | 2022.10.15 |
| [NLP] Perplexity(PPL) and BLEU score (0) | 2022.10.14 |


