
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 백준
- leetcode
- GIT
- FDS
- 프로그래머스
- python
- wandb
- autoencoder
- rnn
- FastAPI
- 완전탐색
- NLP
- 알고리즘
- NaverAItech
- DeepLearning
- datascience
- 네이버AItech
- docker
- pep8
- GitHub Action
- PytorchLightning
- torchserve
- 코딩테스트
- GCP
- Matplotlib
- github
- Kaggle
- Kubernetes
- pytorch
- vscode
- Today
- Total
Sangmun
[NLP] Transformer 본문
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
개요
기존의 Sequence to Sequence에서 LSTM을 활용한 기계번역 방법론을 제안하였으나 길이가 길어지면 성능이 떨어지는 문제가 있어서 Attention 기법을 이용한 방법론이 제안되었다. 이후 2017년에 Attention구조만을 이용한 Encoder & Decoder 구조를 가진 Transformer가 나오게 되었고 모든 NLP 딥러닝의 표준으로 자리 잡게 되었다.


Transformer는 크게 Encoder와 Decoder 그리고 마지막 출력에 softmax함수를 적용해주는 layer가 있으며 각각의 Encoder와 Decoder는 크게 Multi-Head Attention와 FFN layer로 구성되어 있다. Attention is all you need 논문에서는 Encoder와 Decoder를 각각 6개 층으로 쌓아주었다.
* Multihead attention
아래 그림과 같이 [Je, suis, etudiant] 라는 입력이 있을 때 각각의 단어는 embedding layer와 Positional Encoding을 거쳐
Encoder&Decoder의 Multi-Head Attention layer로 들어오게 된다. 그리고 일련의 연산과정을 거쳐 각각의 Attention 값을 계산하게 되는데 과정을 아래와 같다.

과정을 단순하게 하기 위하여 [Thinking, Machines]라는 단어가 들어왔다고 가정하면 두 단어는 embedding layer와 positional encoding을 거쳐 각자 W^q, W^k, W^v 행렬과 연산되어 Query, Key, Value를 계산하게 되고
Query, Key, Value를 이용하여 아래 이미지와 같은 연산과정을 거친 후 Z라는 Attention 값을 가지게 된다.

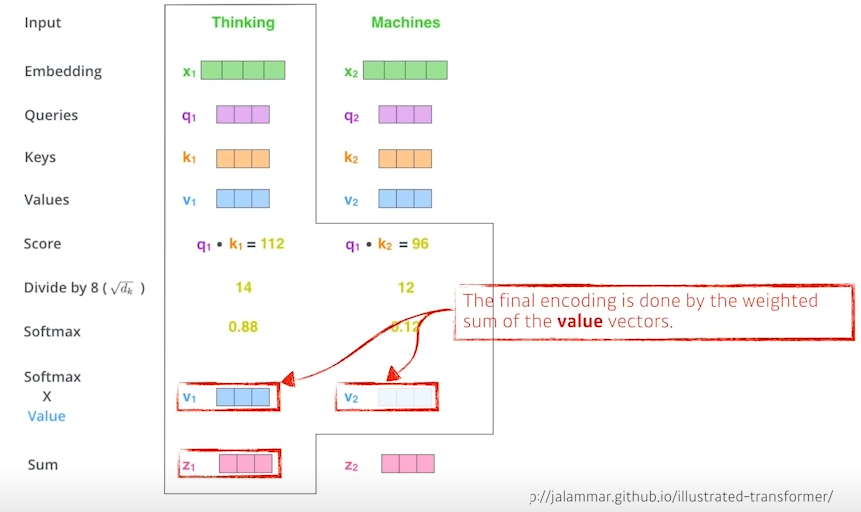
위와 같은 과정을 통하여 8개의 다른 attention을 만들어주게 되고 최종적으로 W^o layer를 거쳐 하나의 단어에 대한 Attention 값이 출력되게 된다.
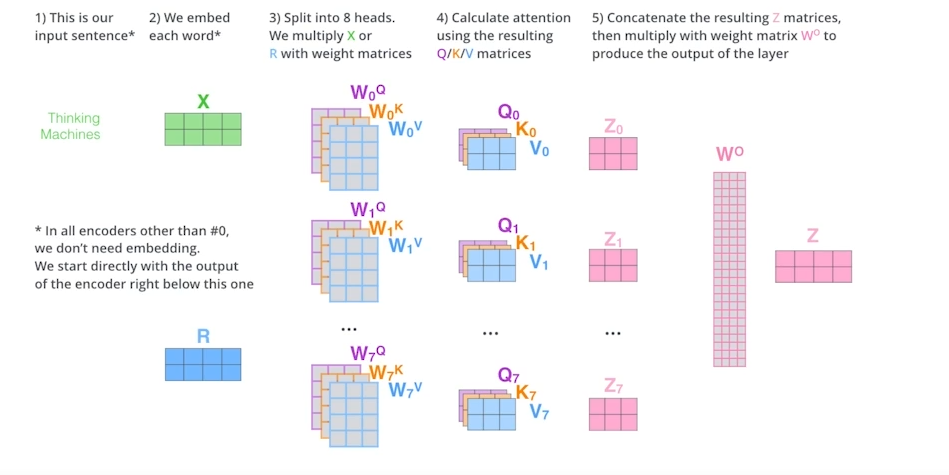
* Positional encoding
Position encoding은 input에서 embedding된 값에 위치정보를 더해주는 값으로 학습이 되어서 결정되는 값은 아니다.
위치에 따라 미리 정해진 값을 단순히 더해주는 것이다. Position encoding을 사용하는 이유는 Attention 레이어는 위치정보를 반영하지 못하기 때문이다. 예를 들어 입력으로 [a, b, c]가 들어오는 케이스와 [c, b, a]가 들어오는 케이스가 있다고 치면 self attention layer를 거쳐 나오는 값은 단순히 순서만 바뀐 attention 값이 출력되게 된다. 하지만 경우에 따라서는 같은 단어로 구성되어도 순서가 바뀌었을 때 다른 의미가 될 수가 있기 때문에 positional encoding값을 더해주는 것이다.


* Encoder
아무튼 위와 같은 과정으로 나온 Attention값은 아래와 같은 과정을 거쳐 하나의 Encoder 출력값을 가지게 된다.

과정을 수식으로 표현하면 아래와 같다. i는 encoder의 layer를 의미한다.
$$ h^{enc}_{0,1:m} = emb(x_{1:m}) + pos(1,m) $$
$$ \tilde{h}^{enc}_{i,1:m} = LayerNorm(Multihead_i(Q,K,V) + h^{enc}_{i-1,1:m}), \; where \; Q = K = V = h^{enc}_{i-1,1:m} $$
$$ FFN(h_{i,t}) = ReLU(h_{i,t}\cdot W^1_i)\cdot W^2_i $$
$$ where \; W^1_i \in \mathbb{R}^{d_{model}\times d_{ff}} \; and \; W^2_i \in \mathbb{R}^{d_{ff}\times d_{model}} $$
$$ h^{enc}_{i,1:m} = LayerNorm([FFN(\tilde{h}^{enc}_{i,1});\cdots ;FFN(\tilde{h}^{enc}_{i,m})] + \tilde{h}_{i,1:m}) $$
* Decoder
이렇게 나온 Encoder의 Key와 Value 값은 Decoder의 Attention의 입력값으로 들어가 Encoder와 같은 연산을 수행해주게 된다.
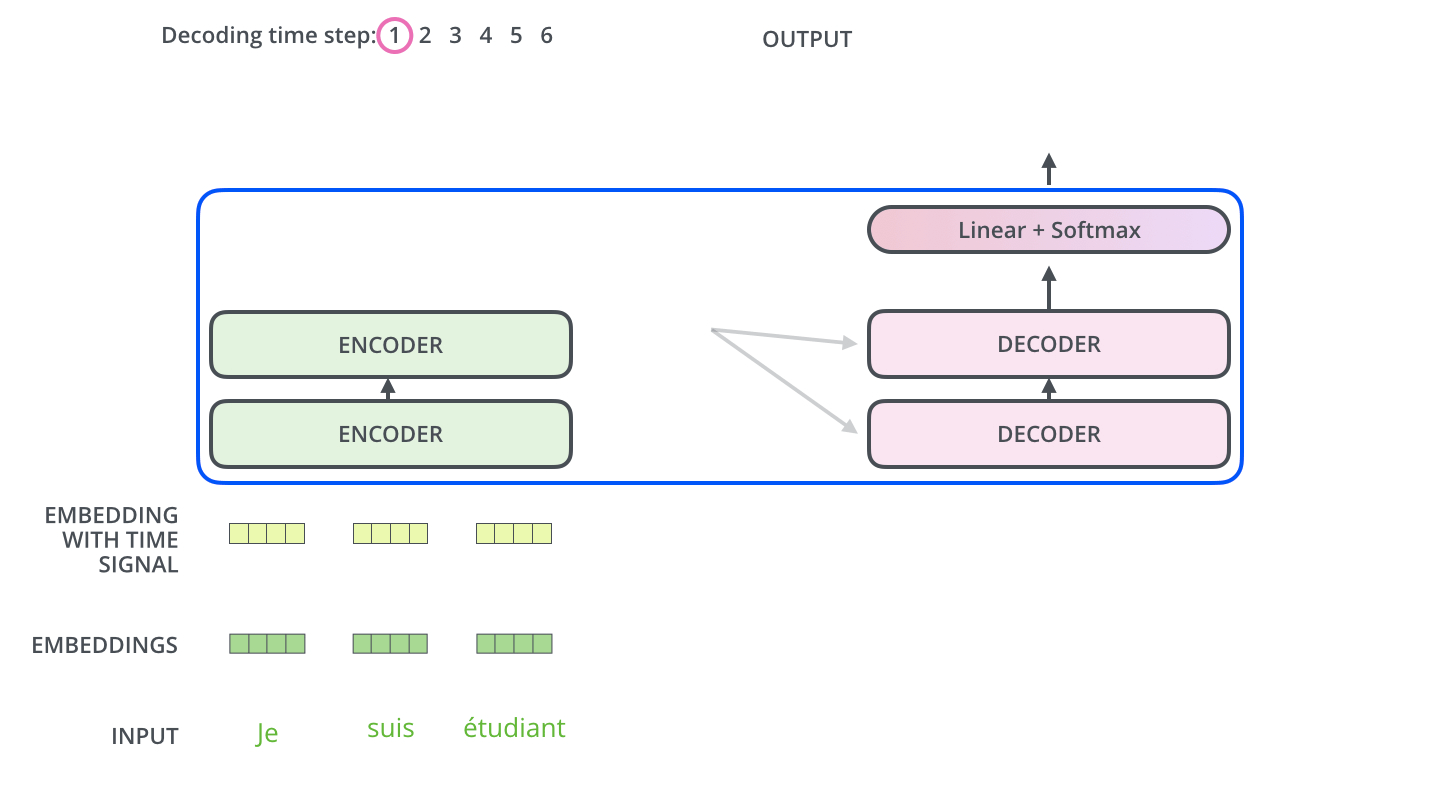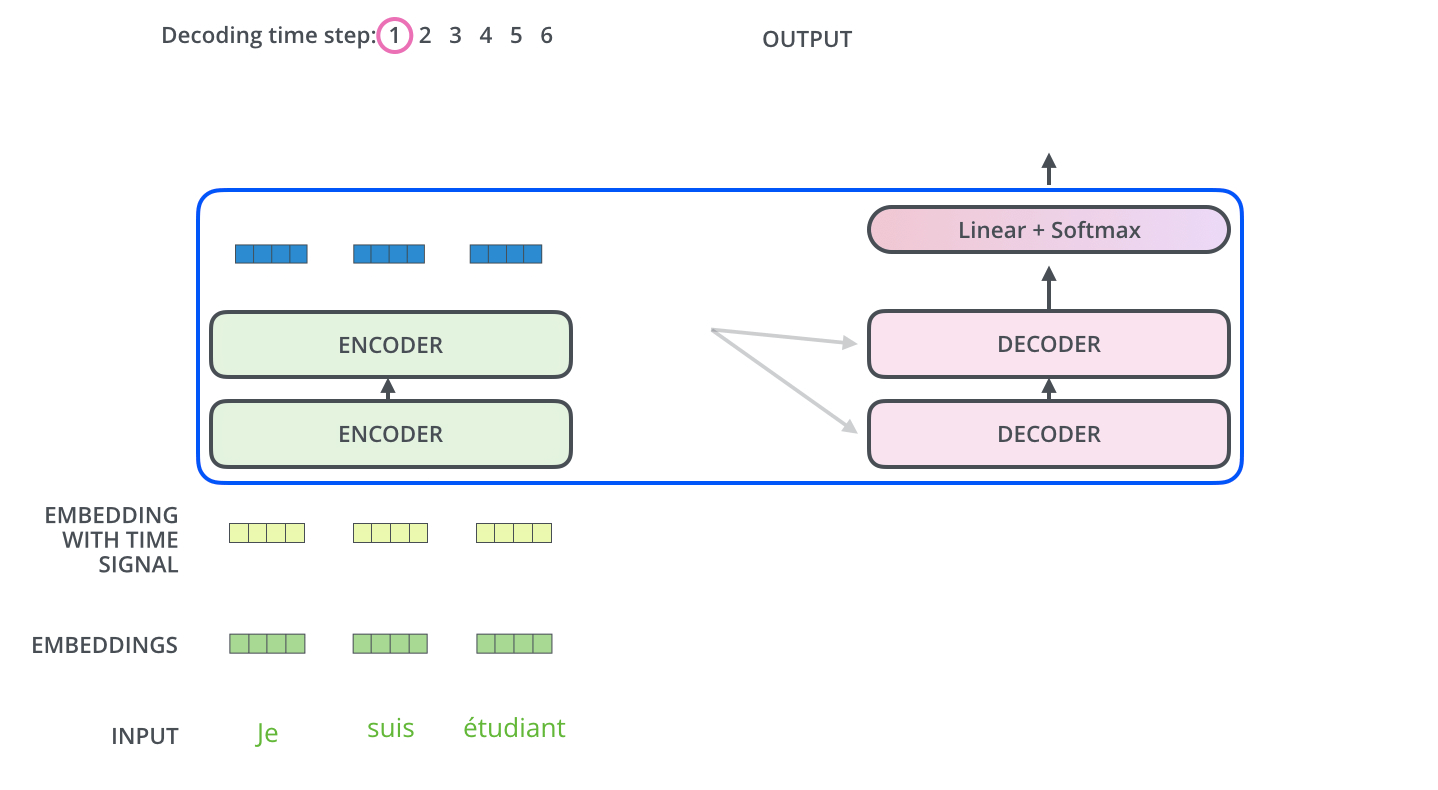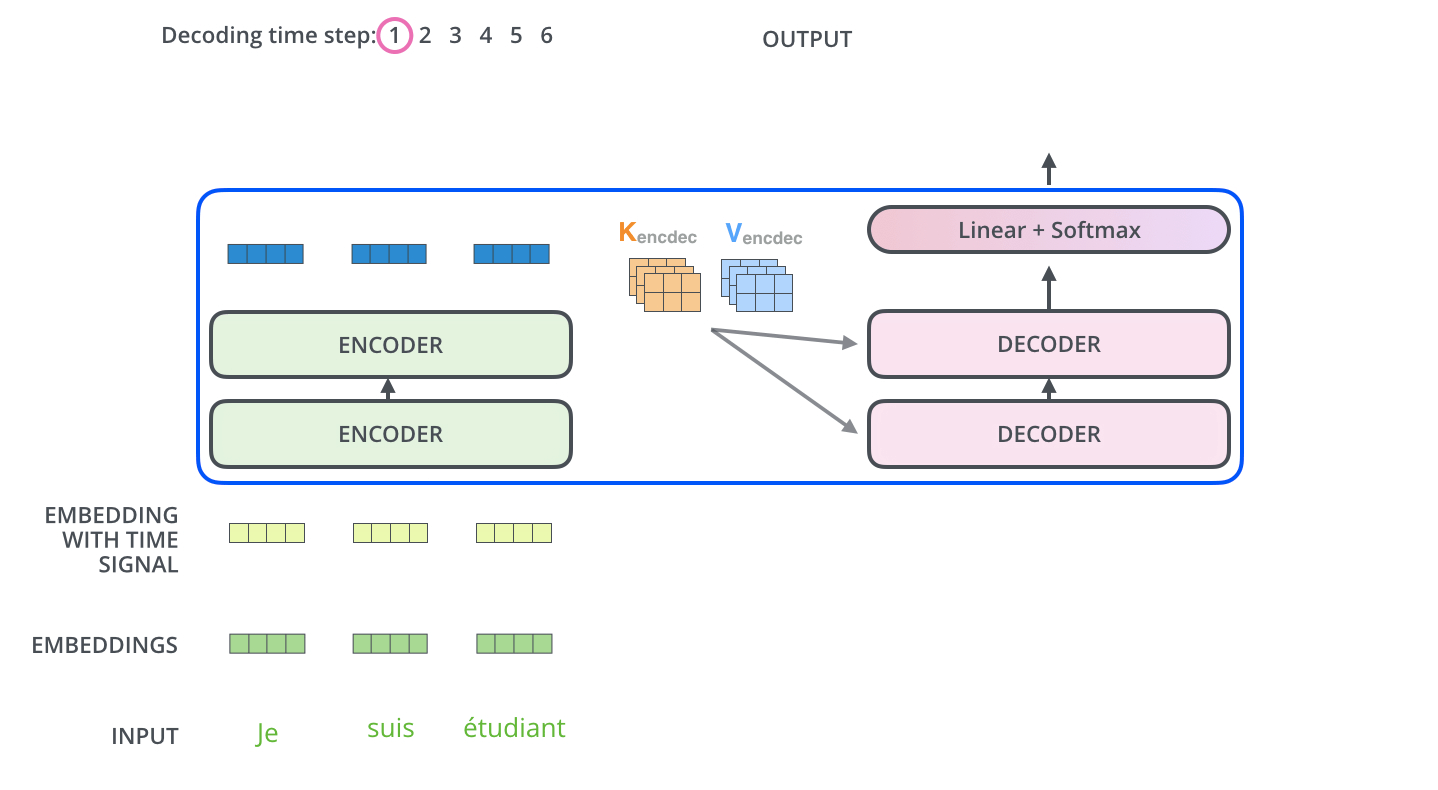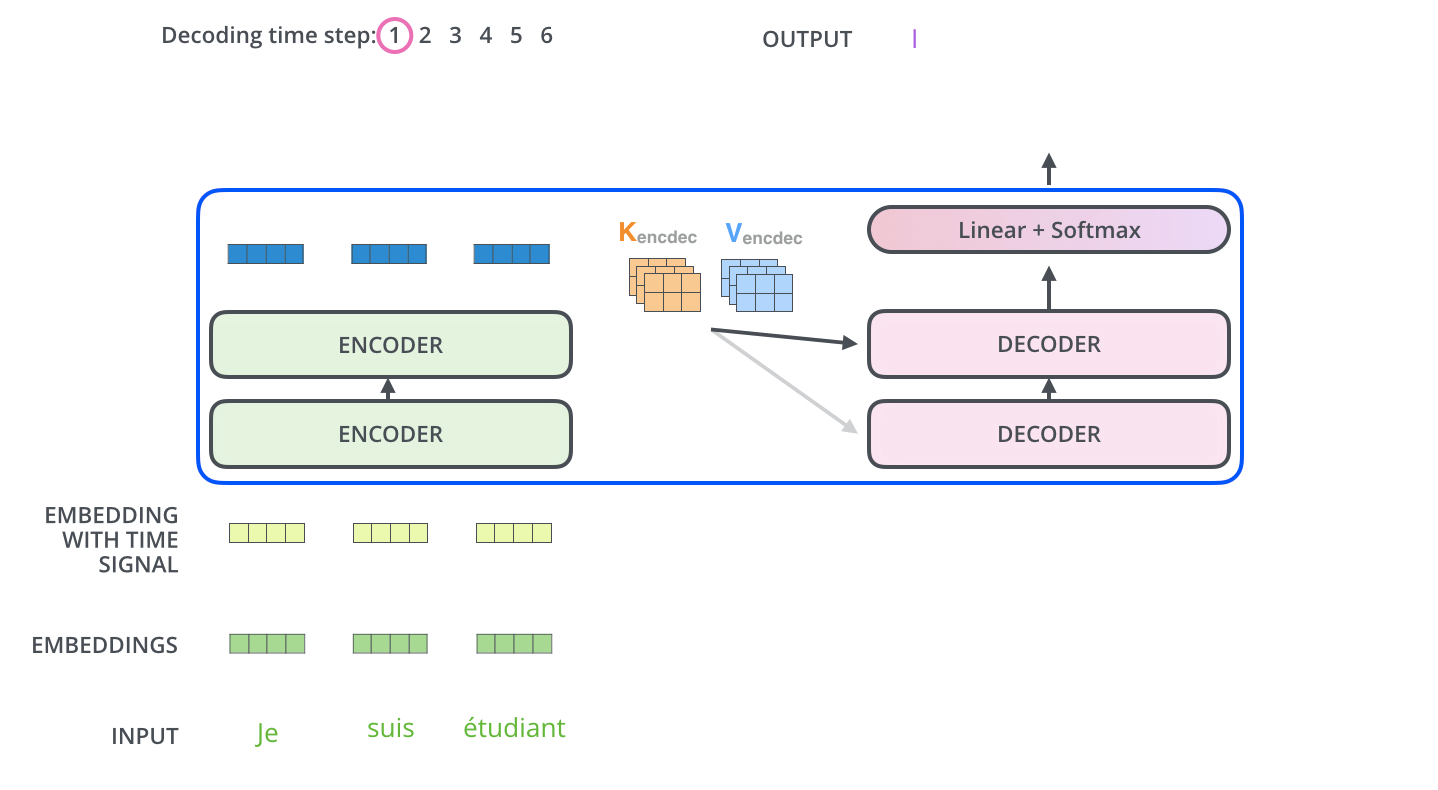

또한 Decoder의 첫번째 Attention은 Masked Multi-Head Attention인데 이는 Decoder는 Auto Regressive 한 성질을 가졌기 때문이다. 설명하자면 Encoder는 입력으로 들어온 모든 타입 스텝에 대하여 Attention연산을 수행할 수 있지만 Decoder는 이전 타임 스텝의 출력 값으로 나온 값이 이번 타임 스텝의 입력값으로 들어온다. 즉 미래 시점의 타임 스텝으로는 어떠한 입력이 들어올지 알 수가 없고, 알 수 없으니 Attention 연산을 수행할 수 없다.

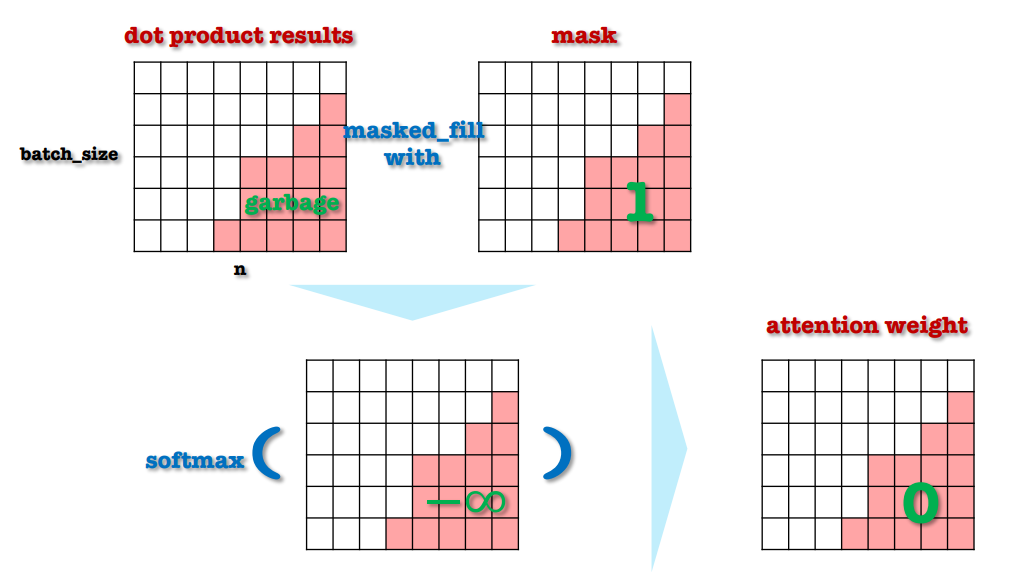
그러므로 배치에 위의 이미지와 같이 mask를 적용을 해주어 Decoder에서 미래 타임스텝에 Attention 연산을 수행할 때 아무런 값이 출력이 안되도록 attention weight를 0으로 적용해주어야 한다.
* Final linear layer & softmax
아래 그림과 같이 최종적으로 Decoder의 출력값에 Linear layer와 Softmax를 통과시켜 하나의 단어를 예측하게 된다.
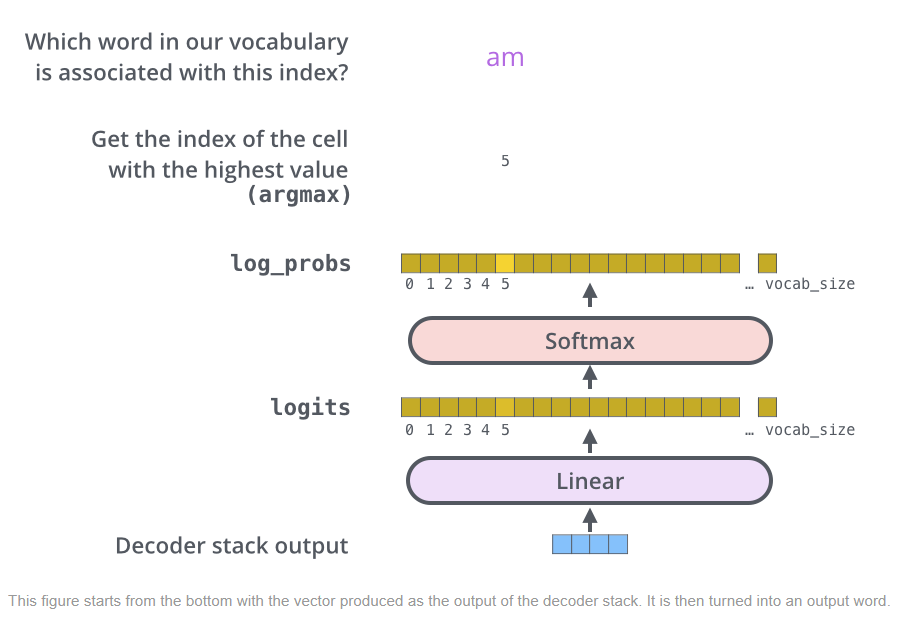
출처 : https://jalammar.github.io/illustrated-transformer/ , # 패스트캠퍼스
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep
jalammar.github.io
# 패스트캠퍼스
'네이버 AI 부스트캠프 4기' 카테고리의 다른 글
| [NLP] Perplexity(PPL) and BLEU score (0) | 2022.10.14 |
|---|---|
| [NLP] Seq2Seq (0) | 2022.10.04 |
| Pytorch Custom Dataset (2) | 2022.09.30 |
| 구글 colab vscode에서 접속하기(ngrok) (0) | 2022.09.29 |
| Pytorch Project Template (0) | 2022.09.29 |



