
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 완전탐색
- python
- 알고리즘
- Kaggle
- GIT
- wandb
- NLP
- FDS
- 백준
- Matplotlib
- 코딩테스트
- github
- FastAPI
- GCP
- 프로그래머스
- pytorch
- GitHub Action
- NaverAItech
- vscode
- datascience
- autoencoder
- docker
- leetcode
- DeepLearning
- Kubernetes
- rnn
- 네이버AItech
- PytorchLightning
- torchserve
- pep8
- Today
- Total
Sangmun
BN 적용해서 학습 이후 실제 사용시에 주의할 점은 본문
https://mole-starseeker.tistory.com/45
배치 정규화(Batch Normalization)의 설명과 탐구
# 배치 정규화(Batch Normalization)의 기능과 그 효과는? 우선 공변량 시프트(covariate shift) 현상이라는 것을 한 번 살펴보자. 아래 그림을 보자. 층 1에 훈련셋이 입력되면 층 2는 층 1의 가중치에 따라
mole-starseeker.tistory.com
Batch Norm Explained Visually — How it works, and why neural networks need it
A Gentle Guide to an all-important Deep Learning layer, in Plain English
towardsdatascience.com
위와 같은 질문에 답을 하기 위해 구글링을 하던 도중 유익한 자료가 많아서 정리를 해보았다.
Batch normalization이란
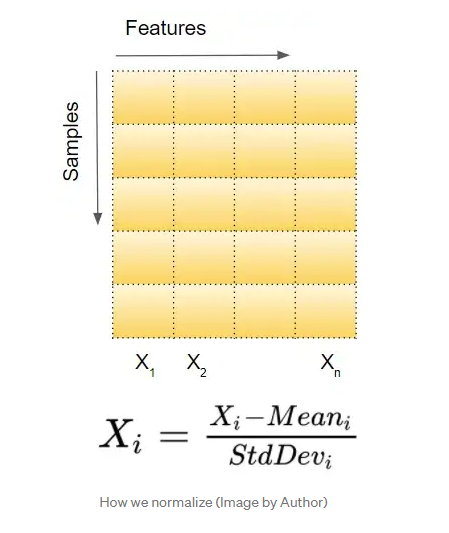
input 데이터를 배치 단위로 평균은 0으로 표준편차는 unit variance로 맞춰주는 것을 말한다.
아래 그림과 같이 Feature 단위로 정규화를 실시해준다.
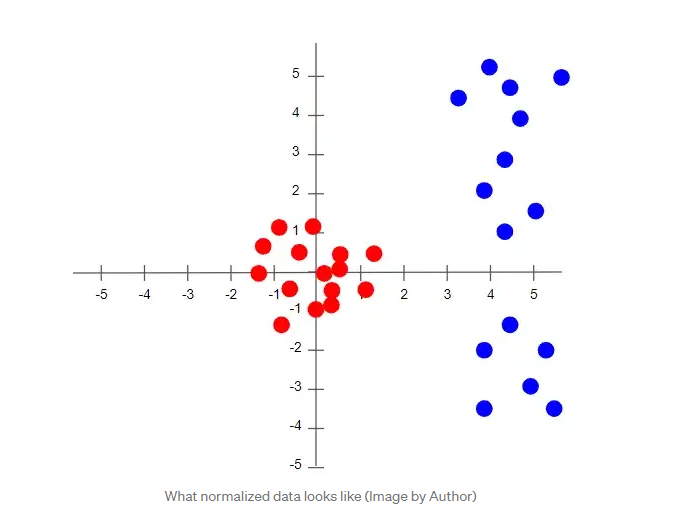
이는 2차원 데이터를 예로 들었을 때 아래의 그림과 같이 기존의 데이터를(파란색) 0 주위로 분포하게(빨간색) 변환하는 작업이다.
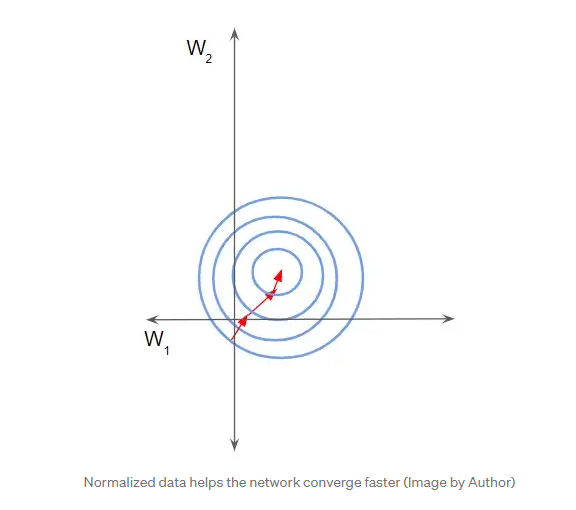
Batch normalization을 실시해주는 이유는 아래의 그림처럼 데이터 분포를 좀 더 고르게 하면서 scale이 큰 데이터의 영향은 줄이고 좀 더 학습이 빨리되게 하는데 그 이유가 있다.

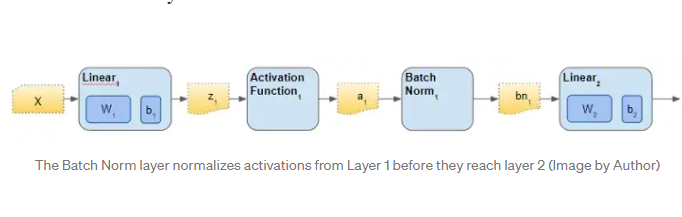
Batch normalization은 어떻게 작동할까
batch normalization은 보통 hidden layer 사이에 놓여서 이전 hidden layer의 ouput을 정규화해준다.
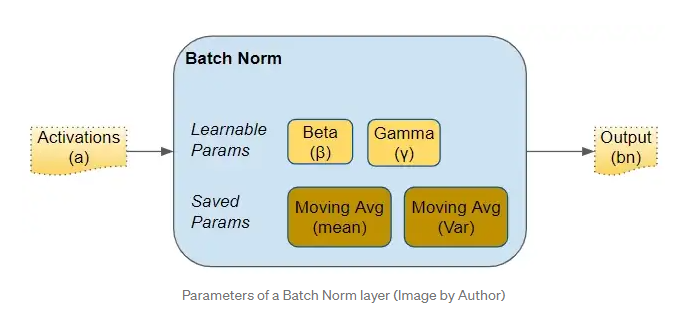
그리고 Batch Norm 내부에는 4개의 파라미터가 있다.
- 2개의 학습이 가능한 beta와 gamma
- 2개의 학습이 불가능함 Mean Moving Average와 Variance Moving Average가 있으며 Batch Norm의 상태를 저장하는 변수이다.
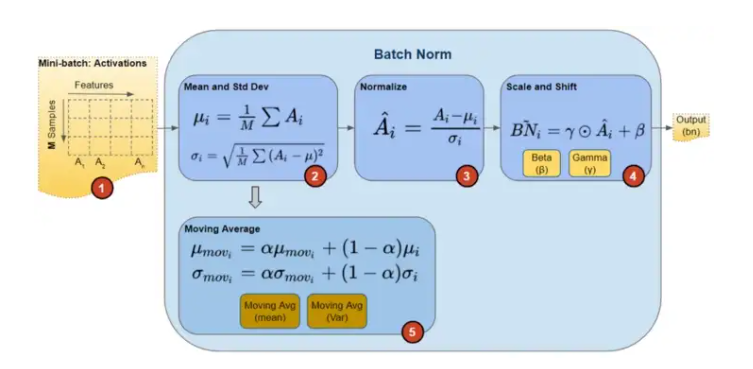
Batch Norm은 학습 시에 아래와 같은 수식으로 위의 4개의 변수들이 계산이 된다
Moving Average의 알파는 Momentum이라고 지칭되며 이는 Optimizer의 Momentum과는 구분되는 Batch Norm만의 하이퍼 파라미터이다.
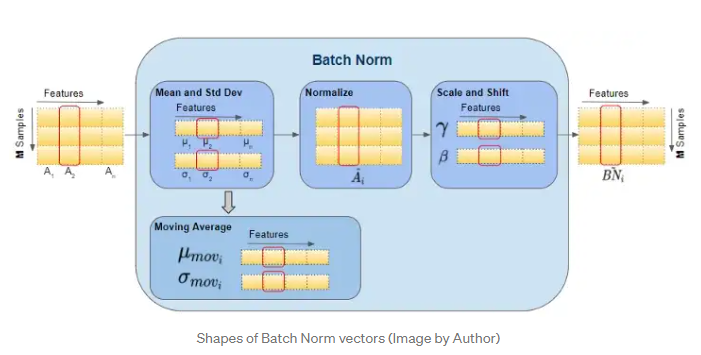
추론 시에 Batch normalization
추론 시에는 Batch Norm에서 평균과 표준편차를 계산해주는 작업을 실시하지 않게 된다. 가령 추론시에는 input data가 하나라면(batch size가 1인 상황) 어차피 평균과 표준편차를 계산할 수 없어 정규화를 하지 못하게 된다.
따라서 추론시에는 이전에 학습하면서 계산되었던 Moving Average를 이용하여 정규화를 하게 된다.
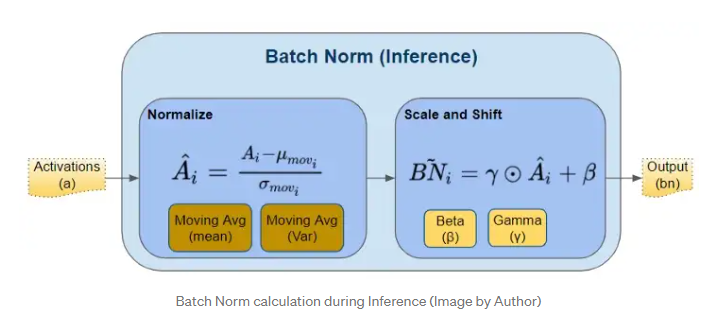

또한 추론시에는 Moving Average를 업데이트하면 안 된다. pytorch BATCHNORM2D 함수를 보면 track_running_stats라는 파라미터가 있는데 해당 파라미터에 False의 값을 주어야 한다.
Batch Norm의 순서
Batch Norm의 순서에는 두 가지 의견이 있다고 한다. Activation function 앞에 두어야 하나 뒤에 뒤에 두어야 하나.
위의 media블로그에서는 activation function 뒤 에두는 것이 더 좋다고 이야기하고 있다.
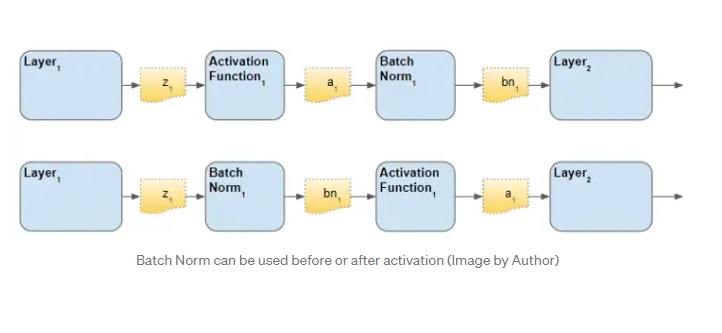
하지만 위의 다른 블로그를 보면 그래프의 분포를 예로 들어 activaton function 이전에 Batch Norm을 적용해주는 것이 좋다고 한다. ReLU로 예를 들면 ReLU는 음의 값은 전부 0으로 처리해버리므로 이후에 Batch Norm을 적용하면 이미 정규화될 수 없는 데이터를 정규화하기 때문이라고 한다.
따라서 좀 더 정규화 분포가 될 가능성이 높은 활성화 함수 이전의 데이터들에 Batch Norm을 적용하는 방법으로 많은 모델의 layer들이 적용되어있다고 한다.
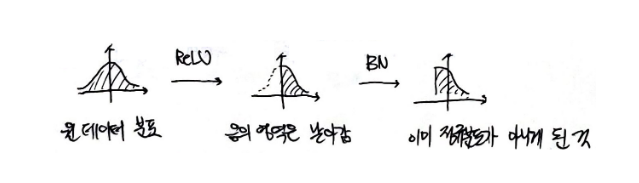
어떠한 방법이 더 나은 방법인지는 활성화 함수마다 케이스가 다를 테지만 이 부분은 차후에 좀 더 심도 있게 알아봐야 할 것 같다.
'네이버 AI 부스트캠프 4기' 카테고리의 다른 글
| Pytorch Lightning 사용법 예제로 알아보기 (0) | 2022.10.25 |
|---|---|
| [NLP] Byte Pair Encoding (0) | 2022.10.20 |
| [DL basic] LSTM & GRU (0) | 2022.10.15 |
| [NLP] Beam Search (1) | 2022.10.15 |
| [NLP] Perplexity(PPL) and BLEU score (0) | 2022.10.14 |


