
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- PytorchLightning
- pytorch
- GitHub Action
- NaverAItech
- docker
- 알고리즘
- GIT
- datascience
- FastAPI
- github
- GCP
- Kubernetes
- vscode
- leetcode
- 프로그래머스
- NLP
- 네이버AItech
- rnn
- python
- pep8
- 완전탐색
- DeepLearning
- FDS
- 코딩테스트
- wandb
- 백준
- Kaggle
- torchserve
- Matplotlib
- autoencoder
- Today
- Total
Sangmun
An Improved Baseline for Sentence-level Relation Extraction 본문
https://arxiv.org/abs/2102.01373
An Improved Baseline for Sentence-level Relation Extraction
Sentence-level relation extraction (RE) aims at identifying the relationship between two entities in a sentence. Many efforts have been devoted to this problem, while the best performing methods are still far from perfect. In this paper, we revisit two pro
arxiv.org
1. Introduction
본 논문은 RE task에 대한 논문이며 RE task의 두 가지 문제점을 다루었다.
RE task는 input데이터가 문장뿐만 아니라 entity name 등의 여러 부가적인 정보를 포함하고 있는데 그동안 제안되었던 방법은 이러한 정보를 충분히 활용하지 않고 있었다.
또한 RE dataset들은 사람이 라벨링을 하여서 제대로 라벨링이 되지 않거나 노이즈가 섞인 데이터가 다수 있었다.
따라서 이러한 점을 개선하여 typed entity marker를 제안하였으며 RoBERTa를 사용하여 TACRED, TACREV, Re-TACRED 데이터셋에서 sota 성능을 달성하였다.
2. Method
* RE task
RE task는 문장단위의 task이며 문장에 포함된 entity 중 entity_suj, entity_obj의 쌍이 주어지면 해당 entity들이 어떠한 관계를 형성하고 있는지를 문맥상 파악하여 사전에 지정된 범주안에서 분류를 하여야 한다. 해당되는 범주가 없으면 관계없음으로 분류된다.
* Architecture
본 논문에서 제안된 기법은 기존에 제안된 PLM 기반의 RE model들의 연장선이며 후술 될 기법을 이용하여 entity span과 entity type을 모델에 입력으로 input_id와 같이 넣어주게 되며 출력으로 나온 hidden_state를 이용하여 loss 값을 계산하게 된다.

* Entity Representation
Architecture에서 언급한 것과 같이, 문장 단위의 RE를 위해서는 문장뿐만이 아니라 subject와 object들의 이름, 구간, NER type도 함께 input으로 넣어주게 되며 이러한 풍부한 정보를 PLM이 학습을 하도록 유도하고 있다.
아래는 논문에서 제안된 구체적인 기법의 종류이다.
- Entity mask
- subject와 object를 각각 [SUBJ-TYPE], [OBJ_TYPE]로 교체를 한다. 이 방법은 SpanBERT에서 모델이 훈련 중 특정 entity에 overfitting 하는 것을 방지한다고 주장한다.
- Entity marker
- [E1], [/E1], [E2], [/E2]를 special token으로 추가하여 subject와 object를 각각 감싸준다.
- Entity marker (punk)
- Entity marker와 달리 special token을 추가하지 않고 subject와 object를 감싸는 토큰으로 @, #과 같은 punctuation을 사용한다.
- Typed entity marker
- <S:TYPE>, </S:TYPE>, <O:TYPE>, </O:TYPE> 같은 special token들을 추가를 하여 subject와 object를 감싸준다.
- Typed entity marker (punct)
- typed entity marker와 같은나 special token을 추가하지 않고 punctuation을 이용하여 감싸준다.

3. Experiments
본 단락에서는 우선 어떠한 Entity Representation이 가장 좋았는지 확인하고 이후에 가장 좋은 기법을 활용하여 그동안 제안되었던 다른 모델들과의 비교 결과를 제시한다.
* Dataset
- Original TACRED : 기존의 TACRED 데이터세트이다.
- TACREC : 기존의 TACRED 데이터세트에서 6.62%의 데이터가 noisily-labeled 되었고 dev set과 test set에 대하여 relabel 한 데이터세트이다.
- Re-TACRED : TACRED에서 label을 재정의 하고 label도 전부 새롭게 한 데이터세트이다.
* Analysis on Entity Representation

따라서 결과를 보면 typed entity가 그렇지 않은 기법보다 성능이 월등했다는 것을 확인할 수 있으며, entity의 category를 제공해 주는 것이 모델의 성능에 크게 영향을 미침을 알 수 있다.
또한 RoBERTA 모델에 대하여 special token을 추가해 주는 것이 모델 성능에 안 좋은 쪽으로 영향을 미쳤다는 것을 확인할 수 있다.
* Comparison with Prior Methods
비교를 한 모델은 아래와 같다.
- LSTM
- C-GCN : 문장 내 의존관계 트리를 graph convolution network에 학습시킨 모델
- SpanBERT : Span단위의 mask를 사용해서 사전학습을 한 bert
- KnowBERT : entity linker와 language model을 jointly 하여 사전학습한 모델
- LUKE : large text corpora와 지식그래프를 활용하여 사전학습한 모델
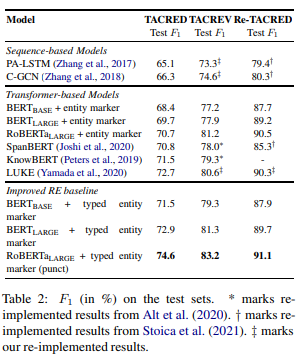
결과는 위의 표와 같으며 RoBERta_larger에 type entity marker(punct)를 적용한 모델이 가장 성능이 좋았음을 확인할 수 있다. 하지만 Re-TACRED에서 얻은 성능 증가분이 TACRED보다 적음을 확인할 수 있다.
이것은 TACRED 데이터세트의 노이즈가 entity에 대한 부가적인 정보를 주는 쪽으로 편향이 되었다고 본 논문은 추측을 하고 있다.
4. Conclusion
따라서 본 논문에서는 매우 간단한 RE task에 유용한 entity representation 기법을 제안하였고 sota를 달성을 하였으며 기존의 TACRED 데이터세트에 노이즈가 어떠한 영향을 미치는지도 본 논문을 통하여 확인을 하였다.



