
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- rnn
- python
- github
- vscode
- DeepLearning
- 프로그래머스
- Kaggle
- torchserve
- GitHub Action
- PytorchLightning
- 완전탐색
- wandb
- 백준
- pep8
- GCP
- FDS
- NLP
- 코딩테스트
- FastAPI
- datascience
- 네이버AItech
- 알고리즘
- GIT
- Kubernetes
- pytorch
- docker
- leetcode
- Matplotlib
- autoencoder
- NaverAItech
- Today
- Total
Sangmun
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks 본문
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
상상2 2022. 11. 19. 20:53https://arxiv.org/abs/1901.11196
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
We present EDA: easy data augmentation techniques for boosting performance on text classification tasks. EDA consists of four simple but powerful operations: synonym replacement, random insertion, random swap, and random deletion. On five text classificati
arxiv.org
1.Introduction
본논문에서는 NLP task에 적용할 수 있는 일반적인 데이터 증강 기법이 그동안 많이 탐구되지 않았음을 지적하고 보편적으로 적용할 수 있는 데이터 증강 기법을 제안한다. 해당 방법론은 텍스트 분류 그리고 특히 적은 데이터셋에 대하여 효과가 있다고 주장한다.
2. EDA
본 논문은 컴퓨터 비전 태스크에서 영감을 받은 여러가지 기법을 테스트해보았으며 해당 기법들은 아래와 같다.
- Sysnonym Replacement(SR) : stop words가 아닌 단어들 중에서 랜덤으로 선택해서 유의어로 교체
- Random Insertion(RI) : 하나의 단어를 선택하고 그 단어의 유의어를 문장내의 임의의 위치에 삽입. n 번시행
- Random Swap(RS) : 랜덤으로 두개의 단어를 선택해서 위치를 바꾸며 n번 시행한다.
- Random Deletion(RD) : p의 확률값을 가지고 문장 내의 각 단어들을 제거한다.

3. Experiments
* Experiments setup
실험을 한 태스크는 아래와 같다.
- SST-2 : Stanford Sentiment Treebank
- CR : customer reviews
- SUBJ : subjectivity/objectivity dataset
- TREC : Question type dataset
- PC : Pro-Con dataset
실험을 한 모델은 아래와 같다
- LSTM-RNN
- CNNs
* 실험 결과
EDA를 적용하였을 떄 평균적으로 0.8% 정확도가 증가를 하였고 특히 train set이 500개 일 때는 3%의 정확도가 증가를 하였다.

또한 training set size를 달리해서도 실험을 진행해보았다.
training set을 {1, 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100} 비율로 나누어 실험을 진행을 하였으며 결과는 아래와 같다.
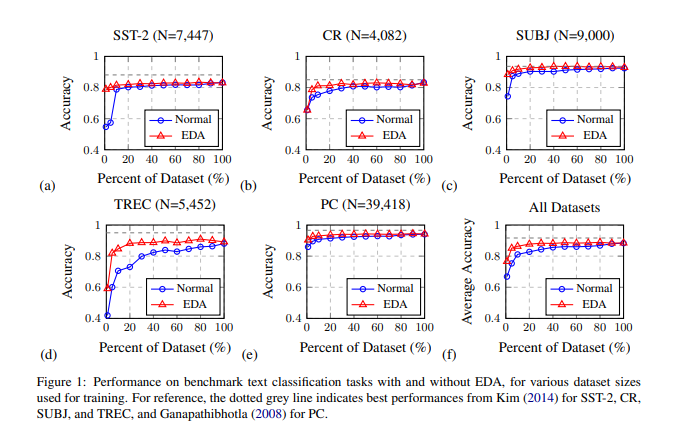
전반적으로 EDA를 적용을 하였을 때 성능이 더 높아지는 것을 확인할 수 있으며 데이터세트의 비율이 적을수록 EDA의 효과가 커지는 것을 확인할 수 있다.
EDA 없이 100%의 데이터세트를 활용을 하였을 때 88.3%의 정확도를 기록했으며 EDA를 적용하였을 때 50%의 기존 데이터세트만으로 훈련을 시켰을 때 88.6%의 성능을 보여주었다.
* EDA를 적용했을 때 기존 라벨의 의미가 보존될까?
EDA를 적용하면 기존 문장의 의미가 변형될 수 있기 때문에 해당 실험을 진행하였다. 먼저 LSTM 모델에 대해서 긍부정 데이터를 학습을 시키고 그다음 테스트세트에 대하여 EDA를 진행하여 각각의 기존 문장에 대하여 추가적인 9개의 데이터를 증강을 하였다. 그 다음 t-SNE를 이용하여 해당 데이터들을 2D로 visualize 하였다. 결과는 기존의 의미가 잘 보존된다는 결과를 보여주었다.

* Ablation Study: EDA Decomposed
또한 각각의 EDA기법 중 어떠한 것이 가장 효과가 좋았는지에 대해서도 실험을 해보았다.

대부분의 기법들이 효과가 있지만 a의 값이 너무 커져 버리면 오히려 성능상 마이너가 되는 지점이 있었다.
또한 성능의 개선은 데이터 세트가 적을 때 더 효과가 있었고 a=0.1일 때가 제일 적절한 파라미터인 것으로 보인다.
* How much augmentation


다음은 한 문장당 증강이 얼마나 증강이 되는 것이 좋은가에 대한 실험이다.
전반적으로 기본 데이터 세트가 적을 때는 보통 오버피팅이 되는 경향이 있음으로 많이 증강을 하는 것이 효과가 좋았으나 큰 데이터 세트에 대해서는 4개의 문장정도를 증강하는 것이 적절하였다.
4. Related Work
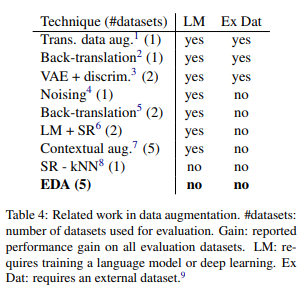
또한 데이터 증강에 대해서 그동안 여러 가지 연구가 있었던 점도 짚어 주고 있으며 본 연구의 장점으로는 데이터를 증강시키는데 추가적인 Language model이나 External datasets가 필요 없다는 점을 장점으로 주장하고 있다.
5. 결론 및 개인적으로 생각하는 한계점
본 연구는 그동안 많이 제안되었던 Synonym Replacement 외에도 다양한 간단하게 시행할 수 있는 데이터 증강 기법들을 제안하였으며 특히 데이터의 개수가 적은 데이터 세트에 대해서 효과가 있음을 보여주었다.
하지만 위의 실험내역에서도 볼 수 있듯이 이미 어느 정도 큰 데이터의 개수를 가진 데이터 세트에서는 큰 효과를 거두지 못하였다. 또한 text classification task에 대한 실험 결과만을 제시하여 다른 task에서는 어떤 효과가 있는지는 보여주지 못했다고 생각한다.
실제로 RE task에 대하여 해당 기법을 실험해 본 결과 오히려 더 좋지 않은 성능을 보여주었다. 따라서 해당 증강기법에 대한 나름의 결론은 적은 데이터세트와 상대적으로 쉬운 task인 classification에서는 해당 기법이 효과가 있을 수 있으나 데이터세트가 많거나 언어에 대한 좀 더 복합적인 이해를 필요하는 task에 대해서는 효과가 없거나 오히려 안 좋을 수도 있다는 것이다.
https://github.com/toriving/KoEDA
GitHub - toriving/KoEDA: Korean Easy Data Augmentation
Korean Easy Data Augmentation. Contribute to toriving/KoEDA development by creating an account on GitHub.
github.com
https://github.com/catSirup/KorEDA
GitHub - catSirup/KorEDA: EDA를 한국어 데이터에서도 사용할 수 있도록 WordNet을 추가
EDA를 한국어 데이터에서도 사용할 수 있도록 WordNet을 추가. Contribute to catSirup/KorEDA development by creating an account on GitHub.
github.com



