
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- PytorchLightning
- 백준
- 코딩테스트
- leetcode
- docker
- Matplotlib
- torchserve
- python
- 완전탐색
- GitHub Action
- FastAPI
- autoencoder
- NLP
- github
- datascience
- 알고리즘
- NaverAItech
- pytorch
- FDS
- Kubernetes
- GIT
- 프로그래머스
- GCP
- Kaggle
- 네이버AItech
- DeepLearning
- wandb
- rnn
- vscode
- pep8
- Today
- Total
Sangmun
[MLOps]wandb sweep 기본 사용법 본문
wandb sweep은 automl의 한 도구로써 하이퍼 파라미터를 찾는 작업을 자동으로 해주는 도구이다.
https://docs.wandb.ai/guides/sweeps/add-w-and-b-to-your-code
Add W&B to your code - Documentation
To create a W&B Sweep, we first create a YAML configuration file. The configuration file contains he hyperparameters we want the sweep to explore. In the proceeding example, the batch size (batch_size), epochs (epochs), and the learning rate (lr) hyperpara
docs.wandb.ai
어째 한국어 매뉴얼보다 영어 매뉴얼이 더 이해하기가 쉬운 것 같다.
sweep을 설정하는 방법은 2가지로 Script안에 포함시키는 방법, config 파일을 설정하여 cli 단에서 실행시키는 방법이 있다.
Script안에 포함
import wandb
import numpy as np
import random
# Define sweep config
sweep_configuration = {
'method': 'random',
'name': 'sweep',
'metric': {'goal': 'maximize', 'name': 'val_acc'},
'parameters':
{
'batch_size': {'values': [16, 32, 64]},
'epochs': {'values': [5, 10, 15]},
'lr': {'max': 0.1, 'min': 0.0001}
}
}
# Initialize sweep by passing in config. (Optional) Provide a name of the project.
sweep_id = wandb.sweep(sweep=sweep_configuration, project='my-first-sweep')
# Define training function that takes in hyperparameter values from `wandb.config` and uses them to train a model and return metric
def train_one_epoch(epoch, lr, bs):
acc = 0.25 + ((epoch/30) + (random.random()/10))
loss = 0.2 + (1 - ((epoch-1)/10 + random.random()/5))
return acc, loss
def evaluate_one_epoch(epoch):
acc = 0.1 + ((epoch/20) + (random.random()/10))
loss = 0.25 + (1 - ((epoch-1)/10 + random.random()/6))
return acc, loss
def main():
run = wandb.init()
# note that we define values from `wandb.config` instead
# of defining hard values
lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochs
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log({
'epoch': epoch,
'train_acc': train_acc,
'train_loss': train_loss,
'val_acc': val_acc,
'val_loss': val_loss
})
# Start sweep job.
wandb.agent(sweep_id, function=main, count=4)전체 예제 코드로 하나하나 살펴보겠다.
sweep_configuration = {
'method': 'random',
'name': 'sweep',
'metric': {'goal': 'maximize', 'name': 'val_acc'},
'parameters':
{
'batch_size': {'values': [16, 32, 64]},
'epochs': {'values': [5, 10, 15]},
'lr': {'max': 0.1, 'min': 0.0001}
}
}먼저 하이퍼 파라미터를 서칭을 설정 파일을 명시하는 것으로 method는 서칭의 방법을 뜻한다.
method는 grid, random, bayes이 있으며 여기서는 랜덤으로 명시되어있다.
parameters 아래에 있는 하이퍼 파라미터들을 랜덤으로 선택하겠다는 의미이다.
즉 batch_size는 [16,32,64], epochs는 [5,10,15], lr은 0.0001 ~ 0.1의 범위에서 매 시행마다 무작위로 선택된다.
name은 해당 시행의 명시된 이름이고 metric은 위의 코드에서 wandb.log를 이요하여 로깅되는 val_acc metric을 최대화하기 위하여 하이퍼 파라미터 서칭을 한다는 의미이다.
그 외 세부적인 사항은 아래의 document에 자세히 나와있다.
https://docs.wandb.ai/guides/sweeps/define-sweep-configuration
Define sweep configuration - Documentation
The brackets for this example are: [3, 3*eta, 3*eta*eta, 3*eta*eta*eta], which equals [3, 9, 27, 81].
docs.wandb.ai
# Initialize sweep by passing in config. (Optional) Provide a name of the project.
sweep_id = wandb.sweep(sweep=sweep_configuration, project='my-first-sweep')다음으로는 해당 설정으로 sweep_id를 발급한다. preject는 본인 계정의 프로젝트 이름이다.
def main():
run = wandb.init()
# note that we define values from `wandb.config` instead
# of defining hard values
lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochs
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log({
'epoch': epoch,
'train_acc': train_acc,
'train_loss': train_loss,
'val_acc': val_acc,
'val_loss': val_loss
})다음으로는 main 코드 안의 내용이며 wandb를 init 해주고 해당 시행 간에 설정된 하이퍼 파라미터로 훈련을 하는 코드이다.
예를 들어 위의 설정 파일에는 하이퍼 파라미터 서칭 방법이 random이고 random으로 lr 0.001, epochs 10, bs 16이 선택되었다면 이번 시행에서는 해당 하이퍼 파라미터를 바탕으로 시행을 한다.
# Start sweep job.
wandb.agent(sweep_id, function=main, count=4)마지막으로 wanb agent에 기존에 발급된 sweep_id를 넘겨주고 진입할 함수를 명시해준다. count는 총 4번 반복한다는 의미이다.
Cli 방식으로 실행
Cli 방식은 script 방식과 전혀 다르지 않으며 실행하는 방식에서만 차이가 있다.
import yaml # yaml을 import 해주어야함
def main():
# Set up your default hyperparameters
with open('./config.yaml') as file:
config = yaml.load(file, Loader=yaml.FullLoader)
run = wandb.init(config=config)
# Note that we define values from `wandb.config` instead of
# defining hard values
lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochsScript 코드에서의 sweep_configuration이 config.yaml 파일로 따로 빼서 작성되었다.
# config.yaml
program: train.py # 진입할 Script
method: random
name: sweep
metric:
goal: maximize
name: val_acc
parameters:
batch_size:
values: [16,32,64]
lr:
min: 0.0001
max: 0.1
epochs:
values: [5, 10, 15]config.yaml 파일의 예시이며 차이점은 문법이 달라졌다는 점과 program 파라미터로 진입할 프로그램을 명시해줘야 한다는 점이다.
이후에 cli 해당 명령어들을 입력해주면서 sweep을 실행하면 된다.
# 출처 document
NUM=5 # numper of repeat
wandb sweep --project sweep-demo-cli config.yaml # sweep id 발급
wandb agent --count $NUM noahluna/sweep-demo-cli/sweepID # sweep_id를 기반으로 실행
실제 사용 사례를 보면 아래와 같다. 아래는 내가 개인적으로 작성한 config.yaml 파일의 parameters 부분이다.
parameters:
batch_size:
values: [16,32,64]
lr:
min: 0.000001
max: 0.00001
epochs:
values: [5, 10, 15]
precision:
values : [16,32]
R_drop :
values : [True,False]
warmup_step:
values : [0.05, 0.1, 0.15]
drop_out:
values : [0.05, 0.1, 0.15]
config file이 있는 곳으로 이동해서 wandb sweep을 시작해 준다.

아래에 노란색으로 명시된 명령어를 실행해주면 wandb sweep이 실시된다.
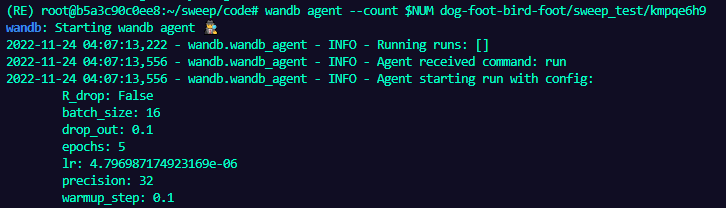
$NUM은 5로 설정해주었으니 총 5번 반복을 하며 이번 시행에서는 아래와 같이 하이퍼 파라미터들이 선택된 걸 볼 수 있다.

보통 딥러닝 Script를 실행할 때 args를 이용하여 하이퍼 파라미터들을 넘겨주곤 하는데 wandb 로그를 보면 위의 이미지와 같은 형태로 wandb sweep에서 선택된 하이퍼 파라미터들을 args를 이용하여 대신 넘겨주는 것처럼 보인다.
'네이버 AI 부스트캠프 4기 > MLops' 카테고리의 다른 글
| [MLOps] mlflow 기본 사용법 (1) (0) | 2022.11.24 |
|---|---|
| [MLOps]pytorch lightning에서 wandb 로깅하기 (0) | 2022.11.24 |
| [MLOps]Pytorch Monitoring tools (weight & biases) (0) | 2022.09.30 |


